数据的准备
原始数据
- 我们使用的原始数据集如下所示。
- 以下数据集是
SicKit Learn中,波士顿房价数据的钱 10 列,可以用如下的代码获取到:
1 | from sklearn.datasets import load_boston |

- 我们使用的原始数据集如下所示。
- 以下数据集是
SicKit Learn中,波士顿房价数据的钱 10 列,可以用如下的代码获取到:
1 | from sklearn.datasets import load_boston |


训练数据:$T = \lbrace (x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N) \rbrace$,
其中,$x_i=(x^{(1)},x^{(2)},\cdots,x^{(n)})^T$,$x_i^{(j)}$是第$i$个样本的第$j$个特征,$x_i^{(j)} \in \lbrace
a_{j1},a_{j2}, \cdots, a_{jS_j} \rbrace$, $a_{jl}$是第$j$个特征可能取到的第$l$个值,$j=1,2,\cdots,n$,$l=1,2,\cdots,S_j$,$y
\in \lbrace c_1, c_2, \cdots ,c_K \rbrace$;
- 训练数据中,共有$N$个数据样本;
- 每个数据共有$n$个特征,即$n$维;
- 第$j$个维度的取值可能有$S_j$种;
- 最终可能的分类有$K$种。
实例:$x$;
实例$x$的分类

| 属性 | 属性值 |
|---|---|
| 输入空间 | $X \subseteq R_n$ |
| 输入变量 | $x \in X$ |
| 输出空间 | $Y = { +1, -1}$ |
| 输出变量 | $y \in { +1, -1}$ |
| 假设空间 | $\mathcal{H}=\lbrace f | f(x)=sign(\omega\cdot x+b)\rbrace$ |

贝叶斯判定该准则被描述为:为了最小化总体风险,只需要在每个样本上选择那个能使条件风险$R(c|x)$最小的类别标记,即:
$$
h^\star (x) = \arg\min_{c \in \mathcal{Y}} R(c | x)
\tag{1}
$$
此时,$h^\star$称作贝叶斯最优分类器。
注:此时的$h^\star$并不是一个可以计算的值,只是一个贝叶斯最优分类器的理论指导。

形式一:
$$
\begin{align}
\min_x \quad & f_0(x) \\
s.t.\quad & f_i(x) \le 0 , \quad i = 1,\dots,m \\
& h_i(x) = 0, \quad i = 1,\dots,p
\end{align}
\tag{1}
$$
$$
\left \lbrace
\begin{matrix}
\omega^T\mathcal{x_1} + b = 0 \\
\omega^T \mathcal{x_2} + b = 0
\end{matrix}
\right .
\to \omega^T(\mathcal{x_1} - \mathcal{x_2}) = 0 \to \omega^T \mathcal{x} = 0
\tag{1}
$$
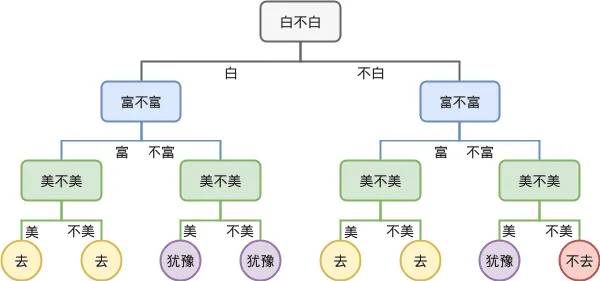
熵(Entropy),在本文中是指信息熵(Information
Entropy),简单的来说,就是指一件事情的不确定性的度量,其单位为(Bit)。相对的,信息的单位也是Bit,刚好是信息熵的反义词,是指一件事情的确定性。
首先,引入熵的计算公式:
$$
Ent(D) = - \sum_k^{| \mathcal{Y} |} P_k log_2{P_k}
\tag{1}
$$

通常情况下来讲,机器学习有如下几个定义:
- 机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。
- 机器学习是对能通过经验自动改进的计算机算法的研究。
- 机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
- 一种经常引用的英文定义是:A computer program is said to learn from experience E with respect to some class of tasks T
and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
