
正则表达式和IndexOf函数的效率问题
事情的起因
事情的起因是一道LeetCode题目,具体如下:
1003. 检查替换后的词是否有效
给定有效字符串 “abc”。
对于任何有效的字符串 V,我们可以将 V 分成两个部分 X 和 Y,使得 X + Y(X 与 Y 连接)等于 V。(X 或 Y 可以为空。)那么,X + “
abc” + Y 也同样是有效的。例如,如果 S = “abc”,则有效字符串的示例是:”abc”,”aabcbc”,”abcabc”,”abcabcababcc”。无效字符串的示例是:”abccba”,”ab”,”
cababc”,”bac”。如果给定字符串 S 有效,则返回 true;否则,返回 false。
我的解答:
1 | /** |
排名第一的解答:
1 | /** |
上述两种解答的思路都是一样的,但是其中一点区别就是,我使用了indexOf来查找和替换字符串中的abc
,但是他用了正则表达式,导致的结果在时间上差了4倍。为了防止个例,我自己编写了一个测试用例来测试了一下,具体如下:
1 | let lengthOfABC = 1000000 |
其中,lengthOfABC表示含有abc的个数,运行结果如下:
1 | When lengthOfABC = 10000(一万) |
从上述运行结果来看,这丫不是个例,在本例中,正则表达式的确要比indexOf快很多。
下面我们尝试分析一下原因。
正则表达式的原理
正则表达式的回溯
在使用贪婪匹配或者惰性匹配或者或匹配进入到匹配路径选择的时候,遇到失败的匹配路径,尝试走另外一个匹配路径的这种行为,称作回溯。
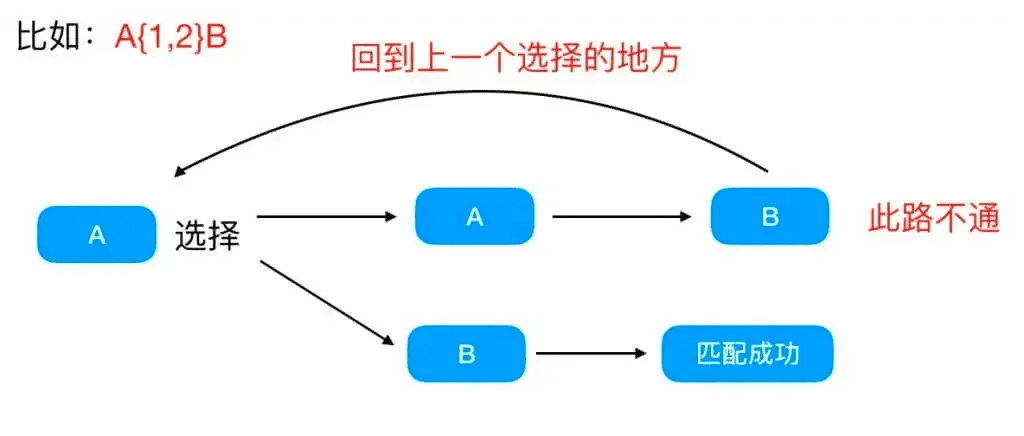
因为正则表达式中,会有模糊匹配,比如:.|*|+等,所以,模糊匹配的时候回造成很大概率的多次回溯问题。
减少回溯或者避免回溯的方式是:
- 优化正则表达式:时刻注意回溯造成的性能影响。
- 使用DFA正则引擎的正则表达式。
传统正则引擎分为NFA(非确定性有限状态自动机),和DFA(确定性有限状态自动机)。
DFA
对于给定的任意一个状态和输入字符,DFA只会转移到一个确定的状态。并且DFA不允许出现没有输入字符的状态转移。
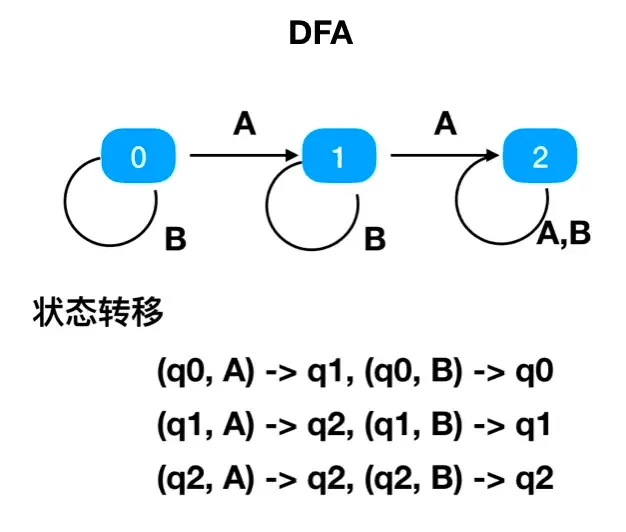
正则里面的DFA引擎实际上就是把正则表达式转换成一个图的邻接表,然后通过跳表的形式判断一个字符串是否匹配该正则。
优点:不管正则表达式写的再烂,匹配速度都很快
缺点:高级功能比如捕获组和断言都不支持
NFA
对于任意一个状态和输入字符,NFA所能转移的状态是一个非空集合。
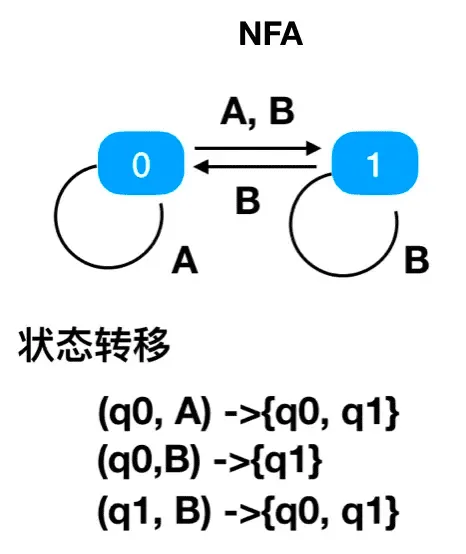
优点:功能强大,可以拿到匹配的上下文信息,支持各种断言捕获组环视之类的功能
缺点:对开发正则功底要求较高,需要注意回溯造成的性能问题
在平常写正则的时候,少写模糊匹配,越精确越好,模糊匹配、贪婪匹配、惰性匹配都会带来回溯问题,选一个影响尽可能小的方式就好。
String.IndexOf源码分析
1 | public |
ECMA 262 -String.Prototype.indexOf
- Let O be ? RequireObjectCoercible(this value).
- Let S be ? ToString(O).
- Let searchStr be ? ToString(searchString).
- Let pos be ? ToInteger(position).
- Assert: If position is undefined, then pos is 0.
- Let len be the length of S.
- Let start be min(max(pos, 0), len).
- Let searchLen be the length of searchStr.
- Return the smallest possible integer k not smaller than start such that k +
searchLen is not greater than len, and for all nonnegative integers j less than searchLen, the code unit at index
k + j within S is the same as the code unit at index j within searchStr; but if there is no
such integer k, return the value -1.
RegExp.prototype [ @@replace ] ( string, replaceValue )
Let rx be the this value.
If Type(rx) is not Object, throw a TypeError
exception.Let S be ? ToString(string).
Let lengthS be the number of code unit elements in S.
Let functionalReplace be IsCallable(replaceValue).
If functionalReplace is false, then
- Set replaceValue to ? ToString(replaceValue).
- Let result be ? RegExpExec(rx, S).
2. If result is null, set done to true. 3. Else,
>
- Append result to the end of results.
2. If global is false, set done to true. 3. Else,
>
2. If **matchStr** is the empty String, then
>
2. Let nextIndex be [AdvanceStringIndex](https://tc39.es/ecma262/#sec-advancestringindex)(S, thisIndex,
fullUnicode).
3. Perform ? [Set](https://tc39.es/ecma262/#sec-set-o-p-v-throw)(rx, "lastIndex", nextIndex, true).
Let accumulatedResult be the empty String value.
Let nextSourcePosition be 0.
For each result in results , do
- Let nCaptures be ? LengthOfArrayLike(result).
2. Set nCaptures to [max](https://tc39.es/ecma262/#eqn-max)(nCaptures - 1, 0). 3. Let matched
be ? [ToString](https://tc39.es/ecma262/#sec-tostring)(? [Get](https://tc39.es/ecma262/#sec-get-o-p)(result, "
0")).
4. Let matchLength be the number of code units in matched. 5. Let position
be ? [ToInteger](https://tc39.es/ecma262/#sec-tointeger)(? [Get](https://tc39.es/ecma262/#sec-get-o-p)(
result, "index")).
6. Set position to [max](https://tc39.es/ecma262/#eqn-max)([min](https://tc39.es/ecma262/#eqn-min)(position,
lengthS), 0).
7. Let n be 1. 8. Let captures be a new empty [List](https://tc39.es/ecma262/#sec-list-and-record-specification-type). 9. Repeat, while n ≤ nCaptures
>
>
2. If **capN** is not **undefined** , then
>
- Set capN to ? ToString(capN).
3. Append capN as the last element of captures. 4. Set n to n + 1. 10. Let namedCaptures be ? [Get](https://tc39.es/ecma262/#sec-get-o-p)(result, "groups"). 11. If functionalReplace is true , then
>
>
- Let replacerArgs be « matched ».
2. Append in list order the elements of captures to the end of
the [List](https://tc39.es/ecma262/#sec-list-and-record-specification-type) replacerArgs.
3. Append position and S to replacerArgs. 4. If namedCaptures is not undefined , then
>
- Append namedCaptures as the last element of replacerArgs.
5. Let replValue be ? [Call](https://tc39.es/ecma262/#sec-call)(replaceValue, undefined, replacerArgs). 6. Let replacement be ? [ToString](https://tc39.es/ecma262/#sec-tostring)(replValue). 12. Else,
>
>
- If namedCaptures is not undefined
, then - Set namedCaptures to ? ToObject(namedCaptures).
2. Let replacement be ? [GetSubstitution](https://tc39.es/ecma262/#sec-getsubstitution)(matched, S, position,
captures, namedCaptures, replaceValue).
13. If position ≥ nextSourcePosition , then
>
>
- NOTE: position should not normally move backwards. If it does, it is an indication of an ill-behaving RegExp subclass
or use of an access triggered side-effect to change the global flag or other characteristics of rx. In such cases,
the corresponding substitution is ignored.
2. Set accumulatedResult to
the [string-concatenation](https://tc39.es/ecma262/#sec-ecmascript-language-types-string-type) of the
current value of accumulatedResult, the substring of S consisting of the code units from
nextSourcePosition (inclusive) up to position (exclusive), and replacement.
3. Set nextSourcePosition to position + matchLength.
If nextSourcePosition ≥ lengthS, return accumulatedResult.
Return the string-concatenation of
accumulatedResult and the substring of S consisting of the code units from nextSourcePosition (inclusive) up
through the final code unit of S (inclusive).
总结
之所以正则表达式比较快的原因,是因为,在最优解中,正则表达式是一个确定值,也就是不管DFA和NFA中,状态和搜索图中的节点均只有一个。所以比较快。
结论:
- 在编写正则表达式的编写过程中,不要写过多的通配符,尽量写的确切一点,比如说:能写
\d就不要写.,能写.就不要写*。 - 在确定或者较为确定关键词的大文本搜索或者替换时,使用正则表达式代替
String.prototype.indexOf,可以达到较快的速度。 - 如果对于自己的正则水平不是特别自信,而且需要实现的功能较为简单,请使用DFA正则引擎。否则,可以使用NFA引擎。
正则表达式和IndexOf函数的效率问题
