React中,负责生命周期的主要方法如下图所示:
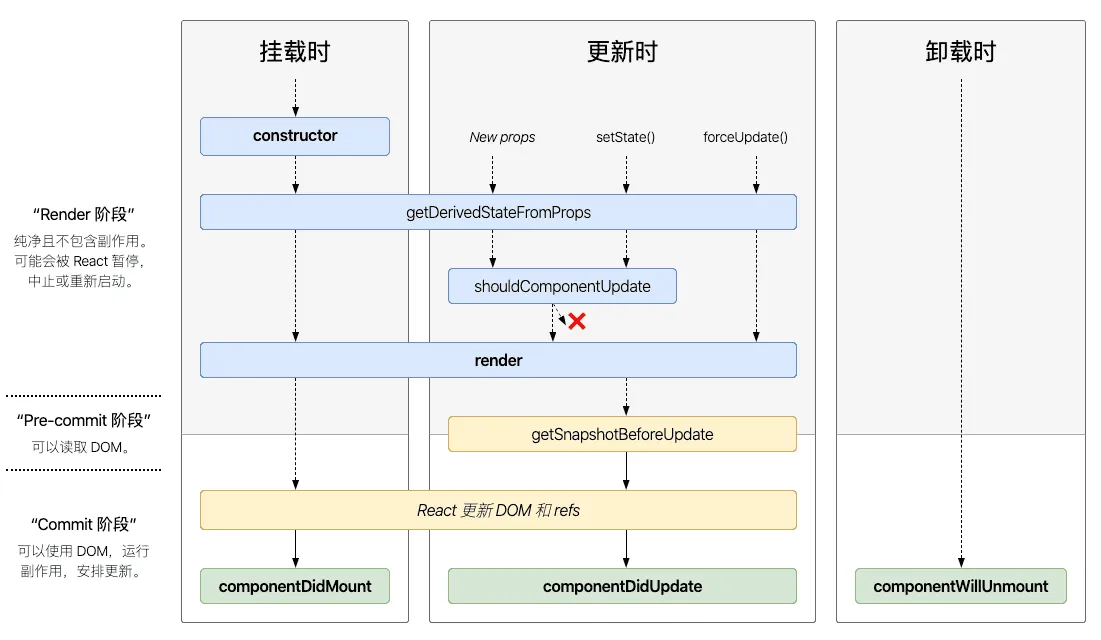
图片来自于:http://projects.wojtekmaj.pl/react-lifecycle-methods-diagram/
话说这么出名的网站竟然不是HTTPs

React中,负责生命周期的主要方法如下图所示:
图片来自于:http://projects.wojtekmaj.pl/react-lifecycle-methods-diagram/
话说这么出名的网站竟然不是HTTPs

本文主要讲解误差逆传播算法的实现。
在将单层感知器转换为多层神经网络之后,其损失函数可以使用下面的军方误差的形式去表示,具体如下:
$$
E_k = \frac{1}{2} \sum_{j=1}^{l} (\hat{y}_j^k - y_j^k)^2
\tag{1}
$$

贝叶斯判定该准则被描述为:为了最小化总体风险,只需要在每个样本上选择那个能使条件风险$R(c|x)$最小的类别标记,即:
$$
h^\star (x) = \arg\min_{c \in \mathcal{Y}} R(c | x)
\tag{1}
$$
此时,$h^\star$称作贝叶斯最优分类器。
注:此时的$h^\star$并不是一个可以计算的值,只是一个贝叶斯最优分类器的理论指导。

形式一:
$$
\begin{align}
\min_x \quad & f_0(x) \\
s.t.\quad & f_i(x) \le 0 , \quad i = 1,\dots,m \\
& h_i(x) = 0, \quad i = 1,\dots,p
\end{align}
\tag{1}
$$
