![应该了解的一些http[s]知识](/assets/images/20200301231911.webp)
应该了解的一些http[s]知识
前置知识
DNS
DNS是指Domain Name System,
即域名系统,是互联网的一项基础服务,我们知道,访问一个系统的话,需要知道对方的IP地址,如此多的IP地址,不方便人们去记忆,所以,我们就有了域名,域名是一串字符,它按照一定的规则映射到IP地址,形成映射,方便人们去记忆,而DNS就是存储这些映射的地方。
DNS一般有如下主要作用:
- 映射IP地址
- 从定向域名或者协议等。
- CDN加速与分流。
- 邮箱业务。
- etc.
具体可以参考:
URL
统一资源定位系统(uniform resource
locator;URL)是因特网的万维网服务程序上用于指定信息位置的表示方法。它最初是由蒂姆·伯纳斯·李
发明用来作为万维网
的地址。现在它已经被万维网联盟编制为互联网标准RFC1738。
一般情况下,http协议的URL格式如下:
1 | <Protocal:[http|https]>//<host:[IP|DomainName]>:<Port>/<path>[?QueryString[key=value][&]+] |
当然,还有一些其他协议的URL格式,这些我们就不细说了。如下:
1 | Protocal[ftp/ssh/git/mysql/etc...]//<用户名>:<密码>@<主机>:<端口>/<url路径> |
浏览器发起请求的过程
- 浏览器首先使用 HTTP 协议或者 HTTPS 协议,向服务端请求页面;
- 把请求回来的 HTML 代码经过解析,构建成 DOM 树;
- 计算 DOM 树上的 CSS 属性;
- 最后根据 CSS 属性对元素逐个进行渲染,得到内存中的位图;
- 一个可选的步骤是对位图进行合成,这会极大地增加后续绘制的速度;
- 合成之后,再绘制到界面上。
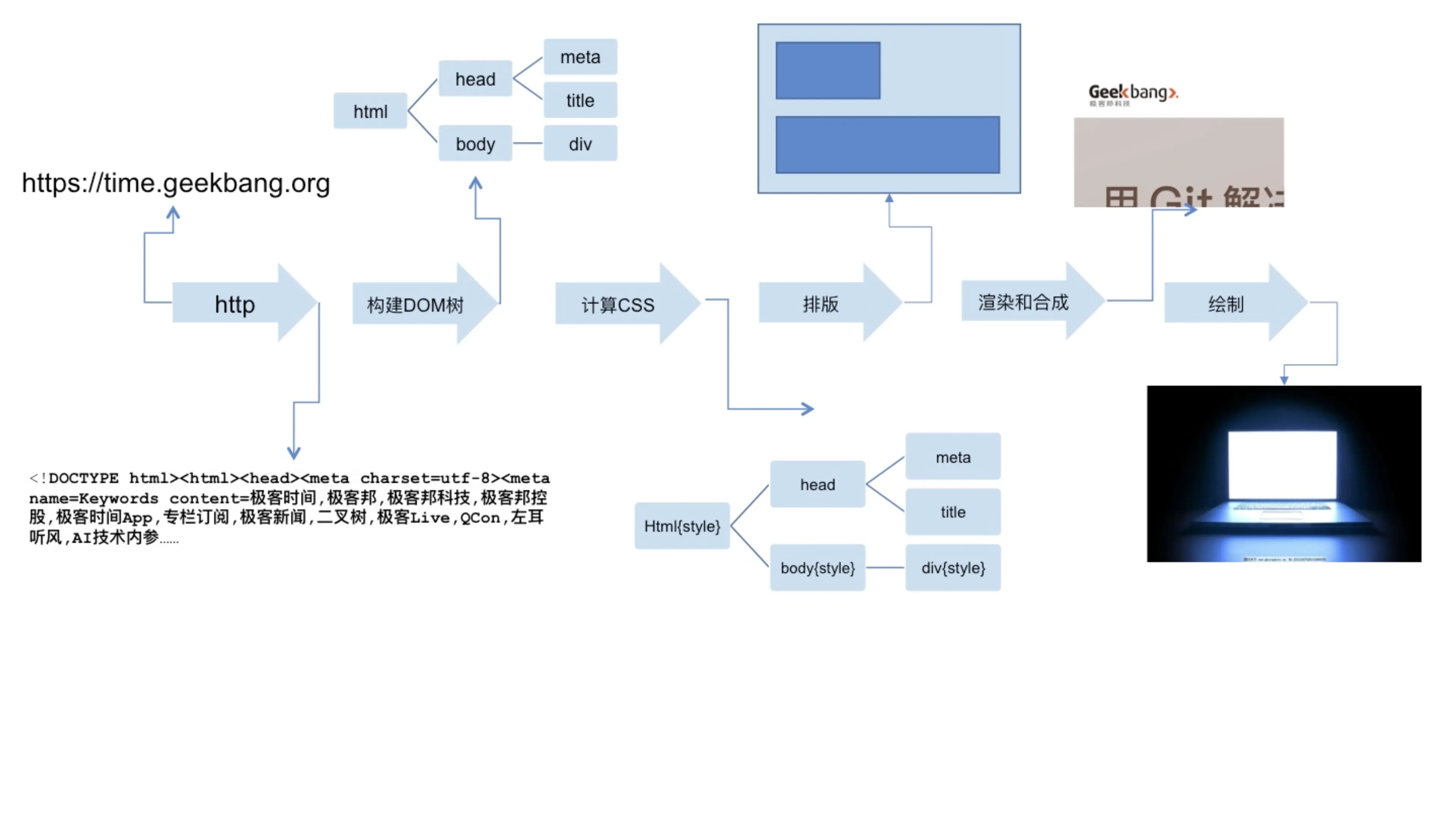
从 HTTP 请求回来,就产生了流式的数据,后续的 DOM 树构建、CSS
计算、渲染、合成、绘制,都是尽可能地流式处理前一步的产出:即不需要等到上一步骤完全结束,就开始处理上一步的输出,这样我们在浏览网页时,才会看到逐步出现的页面。
HTTP中包含的内容
http请求
当浏览器向Web服务器发出请求时,它向服务器传递了一个数据块,也就是请求信息,HTTP请求信息由3部分组成:
- 请求方法URI协议/版本
- 请求头(Request Header)
- 请求正文
下面是一个HTTP请求的例子:
1 | GET /sample.jsp HTTP/1.1 |
请求方法URI协议/版本
请求的第一行是“方法URL议/版本”:GET/sample.jsp HTTP/1.1
以上代码中“GET”代表请求方法,“/sample.jsp”表示URI,“HTTP/1.1代表协议和协议的版本。
根据HTTP标准,HTTP请求可以使用多种请求方法。例如:HTTP1.1支持7种请求方法:GET、POST、HEAD、OPTIONS、PUT、DELETE和TARCE。在Internet应用中,最常用的方法是GET和POST。
URL完整地指定了要访问的网络资源,通常只要给出相对于服务器的根目录的相对目录即可,因此总是以“/”开头,最后,协议版本声明了通信过程中使用HTTP的版本。
请求头(Request Header)
请求头包含许多有关的客户端环境和请求正文的有用信息。例如,请求头可以声明浏览器所用的语言,请求正文的长
1 |
|
请求正文
请求头和请求正文之间是一个空行,这个行非常重要,它表示请求头已经结束,接下来的是请求正文。请求正文中可以包含客户提交的查询字符串信息:
1 | username=jinqiao&password=1234 |
http响应
HTTP响应也由3个部分构成,分别是:
- 协议状态版本代码描述
- 响应头(Response Header)
- 响应正文
下面是一个HTTP响应的例子:
1 | 200 OK |
协议状态代码
描述HTTP响应的第一行类似于HTTP请求的第一行,它表示通信所用的协议是HTTP1.1服务器已经成功的处理了客户端发出的请求(200表示成功)
1 | HTTP/1.1 200 OK |
响应头(Response Header)
响应头也和请求头一样包含许多有用的信息,例如服务器类型、日期时间、内容类型和长度等:
1 | Server:Apache Tomcat/5.0.12 |
响应正文
响应正文就是服务器返回的HTML页面:
1 | <html> |
响应头和正文之间也必须用空行分隔。
响应码
一般来说,响应码用到的也就那么几个,无非是以下类型:
HTTP应答码也称为状态码,它反映了Web服务器处理HTTP请求状态。HTTP应答码由3位数字构成,其中首位数字定义了应答码的类型:
1XX-信息类(Information),表示收到Web浏览器请求,正在进一步的处理中2XX-成功类(Successful),表示用户请求被正确接收,理解和处理例如:200 OK3XX-重定向类(Redirection),表示请求没有成功,客户必须采取进一步的动作。4XX-客户端错误(Client Error),表示客户端提交的请求有错误 例如:404 NOT Found,意味着请求中所引用的文档不存在。5XX-服务器错误(Server Error)表示服务器不能完成对请求的处理:如 500
但是,在这里做一个笔记,以后可以来查:
具体可以参照:MDN:HTTP 响应代码
值得注意的是, 304响应是浏览使用缓存的一个重要的方式,我将会在另一篇文章中说道。
注
在RFC7231中,注明了一些常用的请求头和响应头,具体可以参照:
https://tools.ietf.org/html/rfc7231#section-4
HTTP协议区别
HTTP协议的版本变更
HTTP 0.9
HTTP 0.9 是一个最古老的版本
- 只支持
GET请求方式:由于不支持其他请求方式,因此客户端是没办法向服务端传输太多的信息 - 没有请求头概念:所以不能在请求中指定版本号,服务端也只具有返回 HTML字符串的能力
- 服务端相响应之后,立即关闭TCP连接
HTTP 1.0
随着 HTTP 1.0 的发布,这个版本:
- 请求方式新增了POST,DELETE,PUT,HEADER等方式
- 增添了请求头和响应头的概念,在通信中指定了 HTTP 协议版本号,以及其他的一些元信息 (比如: 状态码、权限、缓存、内容编码)
- 扩充了传输内容格式,图片、音视频资源、二进制等都可以进行传输
在这个版本主要的就是对请求和响应的元信息进行了扩展,客户端和服务端有更多的获取当前请求的所有信息,进而更好更快的处理请求相关内容。
HTTP 1.1
HTTP 1.1 是在 1.0 发布之后的半年就推出了,完善了 1.0 版本。目前也还有很多的互联网项目基于 HTTP 1.1 在向外提供服务。
特性
- 长连接:新增Connection字段,可以设置keep-alive值保持连接不断开
- 管道化:基于上面长连接的基础,管道化可以不等第一个请求响应继续发送后面的请求,但响应的顺序还是按照请求的顺序返回
- 缓存处理:新增字段cache-control
- 断点传输
长连接
HTTP 1.1默认保持长连接,数据传输完成保持tcp连接不断开,继续用这个通道传输数据
管道化
基于长连接的基础,我们先看没有管道化请求响应:
tcp没有断开,用的同一个通道
1 | 请求1 > 响应1 --> 请求2 > 响应2 --> 请求3 > 响应3 |
管道化的请求响应:
1 | 请求1 --> 请求2 --> 请求3 > 响应1 --> 响应2 --> 响应3 |
即使服务器先准备好响应2,也是按照请求顺序先返回响应1
虽然管道化,可以一次发送多个请求,但是响应仍是顺序返回,仍然无法解决队头阻塞的问题
缓存处理
当浏览器请求资源时,先看是否有缓存的资源,如果有缓存,直接取,不会再发请求,如果没有缓存,则发送请求。
通过设置字段cache-control来控制缓存。
断点传输
在上传/下载资源时,如果资源过大,将其分割为多个部分,分别上传/下载,如果遇到网络故障,可以从已经上传/下载好的地方继续请求,不用从头开始,提高效率
HTTP 2
特性:
- 二进制分帧
- 多路复用: 在共享TCP链接的基础上同时发送请求和响应
- 头部压缩
- 服务器推送:服务器可以额外的向客户端推送资源,而无需客户端明确的请求
二进制分帧
HTTP 1.x 的解析是基于文本,HTTP 2之后将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码,提高传输效率
多路复用
在共享TCP链接的基础上同时发送请求和响应,基于二进制分帧,在同一域名下所有访问都是从同一个tcp连接中走,http消息被分解为独立的帧,乱序发送,服务端根据标识符和首部将消息重新组装起来。
头部压缩
由于 HTTP 是无状态的,每一个请求都需要头部信息标识这次请求相关信息,所以会造成传输很多重复的信息,当请求数量增大的时候,消耗的资源就会慢慢积累上去。所以
HTTP 2
可以维护一个头部信息字典,差量进行更新头信息,减少头部信息传输占用的资源,详见 HTTP/2 头部压缩技术介绍。
HTTP/HTTPs
- HTTPS 协议需要申请证书
- HTTP 和 HTTPS 使用端口不一样,前者是80,后者是443
- HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,HTTPS 运行在 SSL/TLS 之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的
- HTTPS 可以有效的防止运营商劫持
- 没有别的区别了
应该了解的一些http[s]知识
