MNIST数据集 MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST).training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50%the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
数据集的划分 MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
数据格式 整个MNIST数据集的格式为一对一的图片和标签对,图片为$[784,1]$的形状,而标签为$[10,1]$(One-Hot编码)。
可以通过下面的代码来查看一下。
1 2 3 4 print ("Train Images Shape:" , mnist.train.images.shape)print ("labels Shape:" , mnist.train.labels.shape)
图像大概就长这个样子:
标签大概长这个样子:
1 2 3 4 5 6 7 8 9 10 [[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. ] [0. 0. 1. 0. 0. 0. 0. 0. 0. 0. ] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0. ] [1. 0. 0. 0. 0. 0. 0. 0. 0. 0. ] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0. ] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0. ] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0. ] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1. ] [0. 0. 0. 0. 0. 1. 0. 0. 0. 0. ] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1. ]]
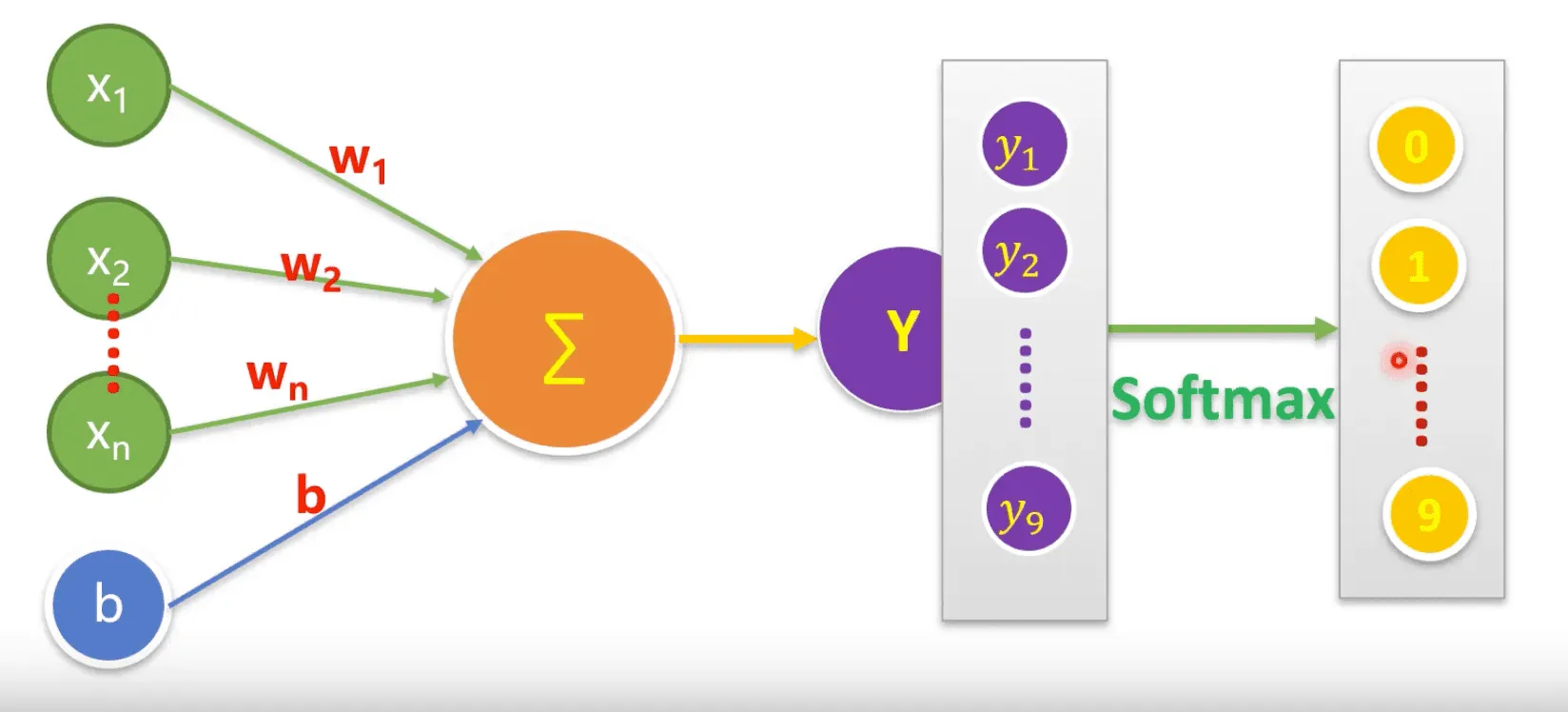
感知机模型
感知机模型的模型公式为:
$$
其实,单一的感知机模型是一个线性模型,如果要真正的做多酚类问题,则需要对其进行SoftMax操作,SoftMax的公式如下:
$$
损失函数的选择 平方损失函数 $$
平方损失函数在带入$Sigmoid$函数之后,会变成一个非凸的函数,不好优化,所以我们在改该例中选择对数损失函数。
对数损失函数 二元逻辑回归一般以对数损失函数作为其损失函数:
$$

交叉熵损失函数 这个损失函数一般用于多元分类问题:
$$
本例很明显是一个0~1的多酚类问题,所以我们使用交叉熵作为我们的损失函数。
使用TensorFlow训练模型 直接上代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 ''' 此处是读入MNIST数据集,并且将数据集中的标签读取成One-Hot格式。 之所以读取为One-Hot格式,是为了方便数值之间的比较,因为其不同标签之间的距离并不能直接表示距离差异,比如说,3-1=2, 8-3=5,但是对于图片来说,8更像3,距离与相似程度不相关,所以,索性使用一些正交基来表示每个向量,这些向量就是十维空间中坐标方向的单位向量。 ''' from tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets("MNIST_data/" , one_hot=True ) ‘’‘ 定义X、Y数据的占位符,其实也就是规定了数据和标签的形状,并且根据形状,挖了俩一模一样的坑,爱存放每一个图像与标签。 ’‘’ x = tf.placeholder(tf.float32, [None , 784 ], name="X" ) y = tf.placeholder(tf.float32, [None , 10 ], name="Y" ) ‘’‘ 定义变量,这里的变量将最终和模型公式一起,形成我们的模型。 ’‘’ W = tf.Variable(tf.random_normal([784 , 10 ]), name="W" ) b = tf.Variable(tf.zeros([10 ]), name='b' ) ‘’‘ 定义前项传递函数 ’‘’ forward = tf.matmul(x, W) + b ‘’‘ 对于结果SoftMax一下,这个生成的就是我们的预测结果。 ’‘’ pred = tf.nn.softmax(forward) ‘’‘ 定义损失函数(使用交叉熵) ’‘’ loss_function = tf.reduce_mean(-tf.reduce_sum(y * tf.log(pred), reduction_indices=1 )) ‘’‘ 定义优化器为梯度下降优化器 ’‘’ optimizer = tf.train .GradientDescentOptimizer(learning_rate) .minimize(loss_function) ‘’‘ 正确率计算公式 ’‘’ correct_prediction = tf.equal(tf.argmax(pred, 1 ), tf.argmax(y, 1 )) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) ’‘’ 初始化TensorFlow会话 ‘’‘ sess = tf.Session() init = tf.global_variables_initializer() sess.run(init) ’‘’ 开练,并且结束 ‘’‘ for epoch in range (train_epochs): for batch in range (total_batch): xs, ys = mnist.train.next_batch(batch_size) sess.run(optimizer, feed_dict={x:xs, y:ys}) loss, acc = sess.run([loss_function, accuracy], feed_dict={ x: mnist.validation.images, y: mnist.validation.labels }) if (epoch + 1 ) % display_step == 0 : print ("训练Epoch: %02d" % (epoch + 1 ), "Loss=" , " {:.9f}" .format (loss), "Accuracy= " , "{:.4f}" .format (acc)) print ("训练结束。" )’‘’ 验证集测试 ‘’‘ accu_test = sess.run(accuracy, feed_dict={ x: mnist.validation.images, y: mnist.validation.labels }) print ("Test Accuracy: %s" % accu_test)’‘’ 测试集测试 ‘’‘ accu_test = sess.run(accuracy, feed_dict={ x: mnist.test.images, y: mnist.test.labels }) print ("Test Accuracy: %s" % accu_test)
Todo: TensorFlow在执行上述训练时的具体流程