
JavaScript引擎的工作原理探析
主流JavaScript引擎
目前主流的JavaScript引擎有以下几种。
| 引擎名称 | 应用平台 |
|---|---|
| V8 | Chrome & NodeJS |
| SpiderMonkey | Firefox |
| Chakra | IE & Edge |
| JavascriptCore | Safari & React Native |
虽然不同的JavaScript引擎对执行和优化代码的细节有一些差别,但是,他们大致都遵循以下的流程:
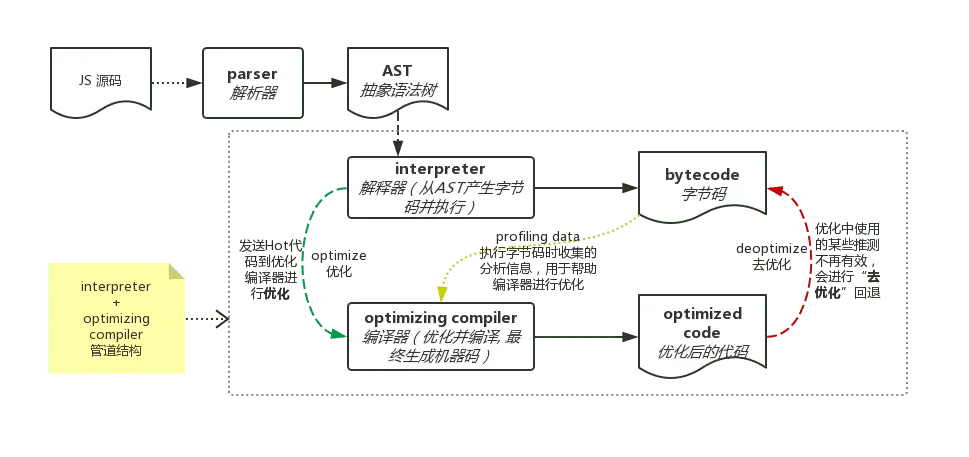
原始的JavaScript代码经过解析器Parser之后,会被转换成抽象语法树(AST,Abstract Syntax Tree)
然后AST经过解释器(Interpreter Ignition)之后会将代码转换成机器码(ByteCode),这样的代码是直接可以让机器来执行的。
对于部分代码,如频繁调用的代码,解释器会联通一些分析信息(ProfilingData)一起交给编译器去优化,优化的结果再送给处理器去执行。
在某个节点发现优化时的特定推测是错误的,编译器也会进行“去优化”而将代码还原给解释器。
| 代码 | 生成者 | 执行者 | 生成效率 | 执行效率 |
|---|---|---|---|---|
| 字节码(ByteCode) | 解释器(Interpreter) | 解释器 | 高 | 低 |
| 机器码(Optimized Code) | 编译器(Optimizer) | 处理器(Processer) | 低 | 高 |
上述过程是一个动态的过程,具体从JavaScript引擎拿到代码之后开始,所有的代码都必须要经过解释器,但是后面的事情,如:那些代码需要解释,那些代码需要编译,这整体是一个启动时间、占用空间、执行效率等多方面的权衡。
整体要保证一点,就是只能让那些最需要优化的代码(如:调用最频繁的HotCode)得到优化。
不同的JavaScript引擎对于解释器和优化器有不同的实现,具体如下:
| JavaScript引擎 | Interpreter | Optimizer |
|---|---|---|
| V8 | Ignition | TurboFan |
| SpiderMonkey | Interpreter | BaseLine + IonMonkey |
| Chakra | Interpreter | SimpleJIT + FullJIT |
| JavaScriptCore | LLInt | BaseLine + DFG + FTL |
虽然它们的解释器和优化编译器看起来有不同的名字,但是所有JS引擎都具有相同的架构:parser(用于生成AST)和解析器+优化编译器的
管道结构
。说是管道结构是因为解析器执行字节码和优化编译器可以并行执行,当解释器把待优化的代码发送给另一个线程的编译器执行优化时,依然可以继续执行当前未优化的字节码;而优化过程完成后优化后的代码将会合流至主线程而后执行经过优化的代码。
JavaScript中的对象模型
在JavaScript中,所有的一切都可以看做是对象,包括JavaScript中的几种基本单一变量类型,ECMAScript规范基本上将所有对象定义为由字符串键值映射到
property 属性的字典,具体有以下几种属性:
[[Value]],保存对象的具体值[[Writable]]决定该属性是否可以被重新赋值[[Enumerable]]决定该属性是否出现在 for-in 循环中;[[Configurable]]决定该属性是否可被删除。
[[双方括号]] 的符号表示看上去有些特别,但这正是规范定义不能直接暴露给 JavaScript 的属性的表示方法。在JavaScript
中你仍然可以通过 Object.getOwnPropertyDescriptor API 获得指定对象的属性值:
JavaScript就是这个定义对象的,那么数组呢?
你可以将数组想象成一组特殊的对象。两者的一个区别便是数组会对数组索引进行特殊的处理。这里所指的数组索引是 ECMAScript
规范中的一个特殊术语。在 JavaScript 中,数组被限制最多只能拥有2^32-1(4,294,967,295)
项。数组索引是指该限制内的任何有效索引,即从 0 到 2^32-2(4,294,967,294)的任何整数。
另一个区别是数组还有一个length属性。接着我们为数组分配了另一个元素,length属性便自动更新。length
属性恰好是一个不可枚举且不可配置的属性。一个元素一旦被添加到数组中,JavaScript便会自动更新length属性的 [[Value]] 属性值。
一般来说,数组的行为与对象也非常相似。
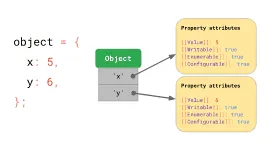

对于其他的类型来说,也拥有类似的结构。
属性的优化访问优化
观察 JavaScript 程序,访问属性是最常见的一个操作。使得 JavaScript 引擎能够快速获取属性便至关重要。
Shapes
在 JavaScript 程序中,多个对象具有相同的键值属性是非常常见的。这些对象都具有相同的形状,因为JavaScript中是没有严格的类的概念的,所以,此处的广义理解可以理解为对象的形状就是一个广义的抽象。
访问具有相同形状对象的相同属性也很常见,考虑到这一点,JavaScript 引擎可以根据对象的形状来优化对象的属性获取。它是这么实现的。
假设我们有一个具有属性x 和y的对象,它使用我们前面讨论过的字典数据结构,它包含用字符串表示的键值,而它们指向各自的属性值。
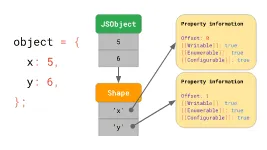
实际上在JS引擎中对象的属性名和属性值是分别存储的,属性值本身被按顺序保存在对象中,而属性名则建立一个列表(Shape),存储*
*每个属性名的“偏移量(offset)”和其他描述符属性**。
如果一个对象在运行时增加了新的属性,那么这个属性名单会过渡到一个新的Shape(只包含了新添加的属性)并链接回原Shape(原文中称为“过渡链”,transition
chains),这样访问属性时如果最新的属性列表中没有找到,可以回溯到上一个列表去检索。
因为存在不同的对象有相同的属性名称列表而重用Shape,当它们发生不同改变会分别过渡到各自的新Shape,形成分叉结构(原文中称为“过渡树”,transition
tree)。
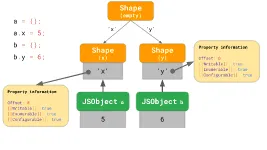
但是如果频繁扩展对象使得Shape链非常长怎么办呢?引擎内部会针对这样的情况再整理一张表(ShapeTable),把所有属性名都列出来然后分别链接至它们所属的Shape…这看起来还是比较繁琐,但都是为了不要浪费“已经做过的工作”,使保留有用的检索信息——Inline
Caches更加方便。
1 | function getX(o) { |
第一次执行时检索Shape,得到offset后取出对象中的值;同时,Shape的链接和这次检索的结果也被内联缓存在代码结构中。
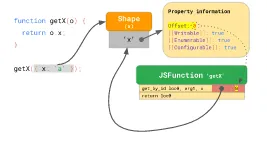
之后再访问时,如果对比Shape还是和之前一样(对象重用Shape的好处),就直接用缓存的offset。
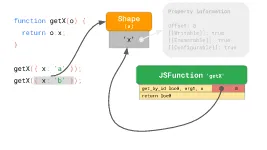
Inline Caches (ICs)
Inline Caches(ICs)是加速执行JS的关键所在,可以理解为为了减少对Hot Code
执行重复检索而缓存下来的重要信息。之所以叫这个名字(内联缓存),大概是因为这种缓存信息是嵌入Hot Code
所在命令的结构中保存的,在每次执行这段代码时进行即时校验和取用。
对于数组来说,有一个既特殊又相似的地方。数组的length属性与对象的属性存储方式相同。而对于数组的元素,本质上也是以字符串(数值)作为key的属性值,且默认情况下与对象自定义属性的描述信息相同(除[[value]]
外,都可写,可枚举,可配置)。
JS引擎会把所有数值索引的元素单独存储在该数组的elements backing store
中,可以理解为它的物品摆放整齐的后备仓库。如果没有人为修改任何索引的属性描述信息,不需要再存储“offset”
,因为通过数值索引访问时索引本身就是“offset”,而属性描述符只需存储一份给每一个索引属性共用。
但是以上是一般的情况,如果不幸遇到了数组索引的描述符被重新定义的情况,即使只是改变了一个,JS引擎也不得不放弃上面的优化策略,它的仓库也不得不变成“字典”一样的结构,为每个元素开辟更大的地方,为其索引属性保存完整的描述信息。这样数组操作相对来说会变得低效。
根据上面的描述,可以产生一个关于数组循环的优化示例,具体如下;
1 | // 每次循环读取arr.length |
上述优化示例的主要关键点在于,每次读取
Array.length的时候,是有开销的。而且数组的规模越大,开销越大。
原型链优化
原型本身也是对象,当通过一个对象访问属性,如果在当前对象没有找到,会沿着原型链向上一级一级查找直到找到或原型为null时停止而返回undefined。
如果把原型和对象一样处理,当访问一个对象的属性,需要先在它本身的Shape中查找是否存在,如果没有,再访问该对象的原型,然后检查原型的Shape,以此类推——每次访问一个原型,相当于要完成
在当前Shape中查找属性和通过对象访问原型两次检索。而实际上,在JS引擎中,**原型的引用被保存在了对象的Shape上而非对象本身
**,这样可以在检查当前Shape中没有目标属性的时候直接链接至下一个原型对象,使每跳转一次原型只需完成一次检索。
但是这样做还是需要沿着原型链检索属性,对于重复访问特定属性的操作优化十分有限。沿着原型链查找属性是比较昂贵的操作,尤其是有很多情况下对象的原型链可能会很长而常用的重要操作都在原型上,比如作者举的HTML中a元素的例子,我们可以用下面代码在console中打印出它的原型链:
1 | function protoChain(node) { |
打印出的结果是:
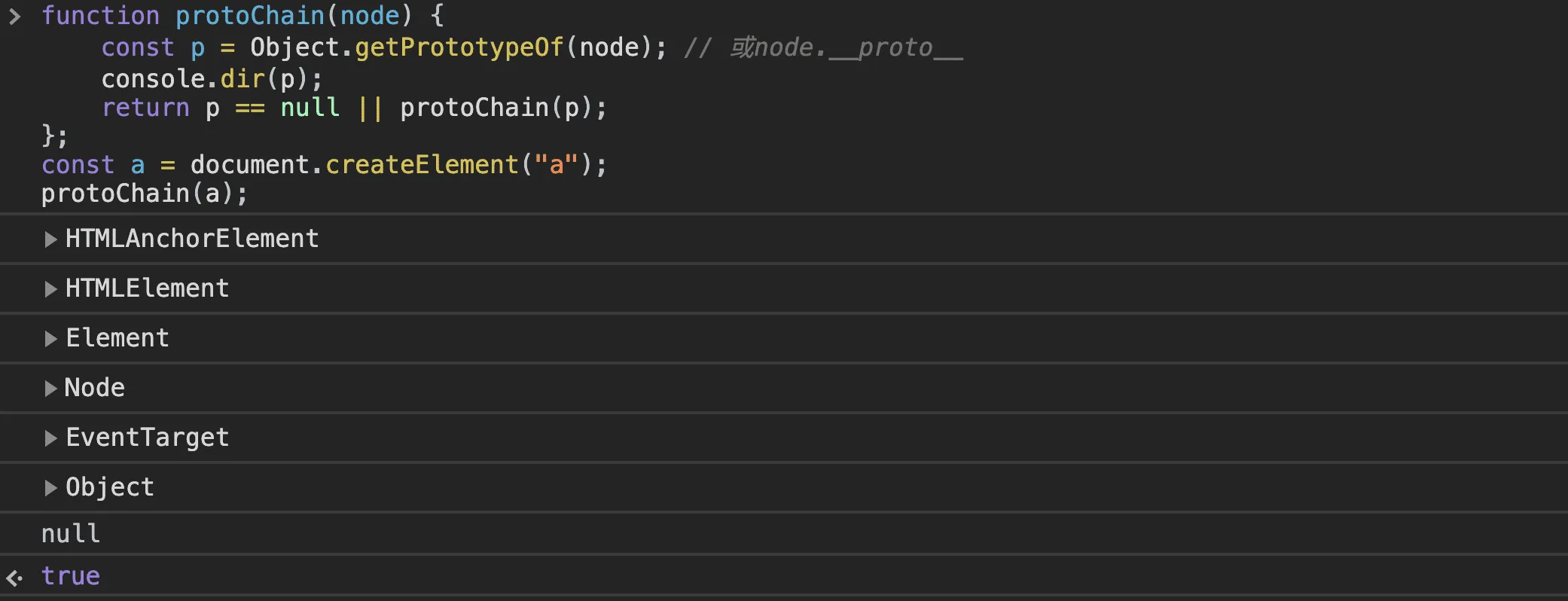
如果目标属性在比较深的原型上,每次检索都是一串昂贵操作。按照对象中缓存属性offset的思路,我们可以把原型上的属性位置也缓存一下,显然同时还必须把这个原型对象也保存一份引用,这样如果下次访问时原型链和原型对象本身没有发生过变化,就可以直接用上次缓存的结果,跳过查找操作。需要注意的是,任何对象的原型可以动态修改,如何确定原型链是否变化了呢?
JS引擎的做法是,每一个原型对象都有一个唯一的Shape(不和任何其他对象重用),Shape上会链接一个校验位(ValidityCell),标记“*
这个原型及其上游的原型链是否发生过变化*
”。当一个原型对象的属性发生变动,那这个原型和原型链中在它下游的所有原型的ValidityCell都会被置为false。所以为了保证缓存有效,只要确认实例对象的直接原型的这个校验位是否依然为true。
所以,除了缓存实例对象本身的Shape链接、offset和目标属性所在的原型对象,还需要保存该实例对象的直接原型的ValidityCell的链接。
比如以下这段代码:
1 | class Bar { |
当执行$getX = foo.getX,实际上是先加载出foo.getX对应的值,然后将其赋值给$getX
,第一步就是访问对象属性的过程,很明显它需要从原型中获取到,那么这段代码的Inline Cache在一次检索后会保存以下信息:
- offset结果—目标属性的内存位置
- 实例对象本身的Shape链接—对象的属性列表和直接原型是否发生过改变
- 目标属性所在的原型对象链接—获取属性值
- 实例对象的直接原型的ValidityCell的链接—确认原型链是否发生过改变
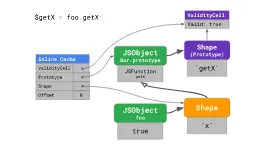
下次调用这段代码时,除了需要对比实例对象的Shape,还要对比原型链上是否有变化,如果都没有改变,那么不再需要检索,直接用缓存的offset取出对应原型对象的属性值即可。这将大大节省查找原型属性所耗费的时间。
而假如此期间修改了原型链的任何一环,原先保存的ValidityCell链接指向的valid值会被置为false,这时缓存就失效了,下次就需要把标准的检索重来一遍。
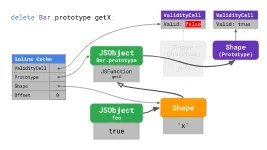
特别需要注意的一点是,当原型链上的原型对象发生改变时,其下游的任何原型对象原先的Shape对应的ValidityCell都会被标记为“无效”。可以想象,在代码执行过程中当Object.prototype
这样的顶级原型被修改时,多少基于原型属性的Inline Cache会失效。
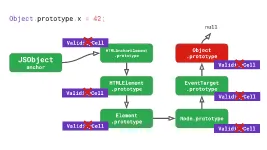
如上面提到过的HTML中a元素的例子,作者有非常形象的示意图:
当执行Object.prototype.x = 42,使顶级原型发生改变:
优化建议
综合以上信息,作者站在引擎的角度给JS开发者以下几方面的建议:
始终以相同的方式初始化对象。
一方面提高Shape的重用性,另一方面尽量降低过渡链或过渡树的长度/深度,缩短沿Shape链检索属性的时间;
不要对数组的元素(数值索引属性)修改属性描述.
这样可以保留引擎对数组的优化处理,使数组的存储和访问更高效;
不要修改原型,尤其是层级较深的原型如Object.prototype等,即使确实有必要修改,也应该在所有代码执行之前修改而不要在代码执行过程中修改。
否则引擎为了保证取到正确的值而不得不放弃之前的内联缓存,重新以最笨的方法重新去查找和获取属性。
参考资料
原文链接:
[JavaScript engine fundamentals: optimizing prototypes](https://mathiasbynens.be/notes/prototypes
中文译版:
[JavaScript 引擎基础:原型优化](https://zhuanlan.zhihu.com/p/42630183
参考:
其他;
JavaScript引擎的工作原理探析
